今回読む論文はCC-BYライセンスで、オープンに公開されています。
著作権(翻訳権?)の関係でメインは私の感想になります。
要約や日本語訳はあまり書けません。ごめんね。

タイトルは
”Large Language Model Influence on Diagnostic Reasoning
A Randomized Clinical Trial”
Ethan Goh, MBBS, MS1,2; Robert Gallo, MD3; Jason Hom, MD4; et alEric Strong, MD4; Yingjie Weng, MHS5; Hannah Kerman, MD6,7; Joséphine A. Cool, MD6,7; Zahir Kanjee, MD, MPH6,7; Andrew S. Parsons, MD, MPH8; Neera Ahuja, MD4; Eric Horvitz, MD, PhD9,10; Daniel Yang, MD11; Arnold Milstein, MD2; Andrew P. J. Olson, MD12; Adam Rodman, MD, MPH6,7; Jonathan H. Chen, MD, PhD1,2,13
JAMA Netw Open. 2024;7(10):e2440969. doi:10.1001/jamanetworkopen.2024.40969
大規模自然言語モデル(LLM)が診断にどう影響するのかとういものですね。
どんな研究?
We performed a randomized clinical trial to compare the diagnostic reasoning performance of physicians using a commercial LLM AI chatbot(ChatGPTPlus[GPT-4]; OpenAI) compared with conventional diagnostic resources(eg, UpToDate, Google).
なんか専用の臨床特化のすんごいLLMとかでてくると期待してたんですが、ChatGPTなんですね。
対称群もUptoDateは使用可能ということで、あんまり差が出ないんじゃないかと期待。
Method
Resident participants were offered $100 and attending participants were offered up to $200 for completing the study.
いいなぁ…
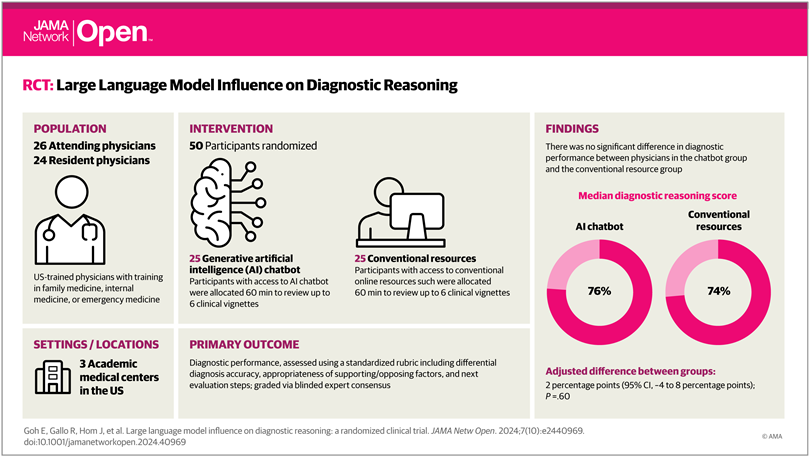
We recruited attending and resident physicians with training in a general medical specialty
(internal medicine, family medicine, or emergency medicine) through email lists at Stanford
University, Beth Israel Deaconess Medical Center, and the University of Virginia.
回答した医師は家庭医(日本だと総合診療医が近い)、内科医、救急医に対して行ったそうです。
ここは科を絞ってもよかったんじゃないかなとも思いますが、そうするとn数が減ってしまうので難しいですね(本研究はn=50)
対称施設はスタンフォード大学、ベス・イスラエル・ディーコネス医療センター、バージニア大学
スタンフォード大学の研修医とか流石に優秀?知らんけど。
ちなみにベス・イスラエル・ディーコネス医療センターはイスラエルではなくてボストンにあるみたいです。

We used the nominal group technique to select across-section of cases; 4 physician authors(E.G., J.A.C., A.P.J.O., and J.H.C.) met to agree on case selection guidelines including preference for abroad range of pathologic settings, avoiding simplistic cases with limited plausible diagnoses, and excluding exceedingly rare cases.
扱った問題(症例)に関して、結構大事かなと思うのは、極端に稀な症例が除外されているってところですかね。
極端な症例って、普通の医者ももちろん苦手なんだけど、LLMも苦手だと思うんですよね(訓練データにないから)
こういうの意外に人間の医者は「なんか変だな」と思って追加検査を選択したりする可能性があるとか思ったり思わなかったり。
Cases were edited to modernize laboratory data reporting conventions and to replace pathognomic phrases(eg, livedo reticularis) with general descriptions(eg,purple,red,lacyrash).
これはどうなんだろう、専門用語をわかりやすい言葉で言い換えるとすると、LLMには有利だけど、医者には関係なさそう。むしろ医者はUptoDateとかGoogle使用okらしいので、その辺の検索能力が低下しそう。
We used a randomized single-blind study design with stratified randomization.
この研究は単盲検試験のようです。
ということは研究実施者(今回は評価者)のバイアスはかかる可能性は一応あります。
Our primary outcome was the final score as a percentage across all components of the structured reflection tool. Secondary outcomes were time spent per case(in seconds) and final diagnosis accuracy.
メインは、鑑別疾患の正確性と根拠、次の診断ステップの3つに基づいて診断能力を評価したスコアの比較。
Secondary outcomeとして、回答時間を比較したようですね。
All statistical analysis was performed using R, version 4.3.2(RFoundationforStatistical
Computing).
どうでもいいところなんだけど、やっぱり統計解析はRがスタンダードなんですね。
最近R触れて無さすぎて何も覚えてません。勉強しないと。
Result
Median years in practice was 3(IQR,2-8).
参加者の特徴なんですけど、ここで自分がうーんと思ったのは、
医師の臨床研究の経験年数の中央値が3年ということです。
ちょっと短くないか?日本だと初期研修が終わって専攻医の段階ですね。
私くらいの経験年数?
そのぐらいだと、自分で意思決定することもありますけど、上司のバックアップがあったり、(経験症例によって)知識にムラがあったりするので、評価に影響するんじゃないかと思いました。
ただ、LLMに対する抵抗の無さという意味では、若手の方がいいかもしれません。
The median score per case was 76%(IQR, 66%-87%)for the LLM group and 74%(IQR, 63%-84%) for the control group.
最初の差はでなさそうという予想は当たりました。
絶対的な正解率に関しては問題の難易度がわからないので検討する意味はなさそうですね。
Median time spent per case was 519(IQR, 371-668) seconds for the LLM group and 565(IQR, 456-788) seconds for the control group(Table 3).
こちらも有意差はありません。
まぁ調べる時間とかLLMにプロンプトを入力する時間とか個人差ありそうだしあまり当てにならなそうですよね。
LLM単体(医師なし)と対称群を比較すると,LLM単体の方が16%診断能力が高いと。で、これが有意差ありなんですね(p=0.03)
In the 3 runs of the LLM alone, the median score per case was 92%(IQR, 82%-97%). Comparing LLM alone with the control group found an absolute score difference of 16 percentage points(95%CI, 2-30 percentage points; P = .03) favoring the LLM alone.
ここがSNS等で一人歩きして話題になっていたところですね。
ていうかMethodにこれ書いてなかった気がするんだけど。急に出てきたな。
これが唯一有意差でた結果になるのかな。
Discussionで具体的に感想述べますが、
別にこれでLLMすごい!人間いらない!とはならないと思います。
Discussion, Conclusion
These findings are particularly relevant now that many health systems offer Health Insurance Portability and Accountability Act–compliant chatbots that physicians can use in clinical settings, often with no to minimal training on how to use these tools.
これはまさにおっしゃる通りですね。
仮にどんなに医療にAIが浸透しても、
現状医療者側がそれを使いこなすスキルを持ってないのが現状です。
少し前に自分が医局でchatGPTを使っていたら、みんな「何それ」みたいな感じでした。
今は流石に何それ、とはならないかな。それでもLLMを使いこなしています!という医師は少ないでしょう。特に導入を決めるようなお偉い先生方は。
An unexpected secondary result was that the LLM alone performed significantly better than both groups of humans, similar to a recent study with different LLM technology. This may be
explained by the sensitivity of LLM output to prompt formulation.
まぁ今回のような文章でのタスクならLLMの超得意分野だからね。
実際の医療現場でLLM最強!とはならないでしょう。
Training clinicians in best prompting practices may improve physician
performance with LLMs. Alternatively, organizations could invest in predefined prompting for
diagnostic decision support integrated into clinical workflows and documentation, enabling synergy between the tools and clinicians.
ここがかなり勉強になった点で、医療者側とLLM側、両方に改善の余地があるということですね。単に優秀なモデルを作ればいいという訳ではないのです。
そして本論文のタイトルだけ見て、間違って解釈していそうな方もいるかもしれませんが、
LLM単独群が医者+LLMよりも有意にスコアが高かったことに関して、
「医者はもういらない!」
「医者がいることで診断能力が落ちている!」
というのは間違っています。実際に本論文の中でも
Results of this study should not be interpreted to indicate that LLMs should be used for diagnosis autonomously without physician oversight.
とあります。
むしろ、LLMと医師の相互作用が機能しきっていない原因を議論するべきです。
例えば、本論文では以下のような改善案が挙げられています。
Given the conversational nature of chatbots, changes in how the LLM inter acts with humans, for example by specifically pointing out features that do not fit the differential diagnosis, might improve diagnostic and reflective performance.
自分としてはどうしたら医師がLLMを使いこなせるようになるのか、というところを解決していきたいですね。
最近は医学部の授業でもプログラミングやったりするところがちょいちょいあるみたいです。
そういう感じでプロンプトエンジニアリングも医学教育に組み込めばいいんですかね。
あとは既存の医師にLLMの使い方を習得してもらうというのは困難な道でしょう。
彼らは日々の臨床業務で一杯一杯ですし、LLMが世間に浸透したことで、LLMのよくない面にも触れつつあります。そういった医師はLLMを受け入れるどころか、むしろ拒絶する傾向にあるのではないかとも思います。
どうにか医療者の負担なく、受け入れられるような形で、AIが医療に統合できるようになって欲しいものです。
The LLM alone out performed physicians even when the LLM was available to them, indicating that further development in human-computer interactions is needed to realize the potential of AIinclinical decision support systems.
Limitation(おまけ)
Given the conversational nature of chatbots, changes in how the LLM interacts with humans, for example by specifically pointing out features that do not fit the differential diagnosis, might improve diagnostic and reflective performance.
ちょっと皮肉入ってる?笑

コメント